Usage of unicode() and encode() functions in Python
 Sophia Terry
Sophia Terry 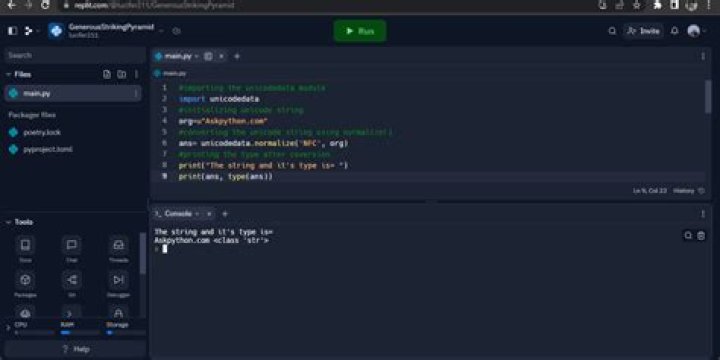
I have a problem with encoding of the path variable and inserting it to the SQLite database. I tried to solve it with encode("utf-8") function which didn't help. Then I used unicode() function which gives me type unicode.
print type(path) # <type 'unicode'>
path = path.replace("one", "two") # <type 'str'>
path = path.encode("utf-8") # <type 'str'> strange
path = unicode(path) # <type 'unicode'>Finally I gained unicode type, but I still have the same error which was present when the type of the path variable was str
sqlite3.ProgrammingError: You must not use 8-bit bytestrings unless you use a text_factory that can interpret 8-bit bytestrings (like text_factory = str). It is highly recommended that you instead just switch your application to Unicode strings.
Could you help me solve this error and explain the correct usage of encode("utf-8") and unicode() functions? I'm often fighting with it.
EDIT:
This execute() statement raised the error:
cur.execute("update docs set path = :fullFilePath where path = :path", locals())I forgot to change the encoding of fullFilePath variable which suffers with the same problem, but I'm quite confused now. Should I use only unicode() or encode("utf-8") or both?
I can't use
fullFilePath = unicode(fullFilePath.encode("utf-8"))because it raises this error:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc5 in position 32: ordinal not in range(128)
Python version is 2.7.2
63 Answers
str is text representation in bytes, unicode is text representation in characters.
You decode text from bytes to unicode and encode a unicode into bytes with some encoding.
That is:
>>> 'abc'.decode('utf-8') # str to unicode
u'abc'
>>> u'abc'.encode('utf-8') # unicode to str
'abc'UPD Sep 2020: The answer was written when Python 2 was mostly used. In Python 3, str was renamed to bytes, and unicode was renamed to str.
>>> b'abc'.decode('utf-8') # bytes to str
'abc'
>>> 'abc'.encode('utf-8'). # str to bytes
b'abc'You are using encode("utf-8") incorrectly. Python byte strings (str type) have an encoding, Unicode does not. You can convert a Unicode string to a Python byte string using uni.encode(encoding), and you can convert a byte string to a Unicode string using s.decode(encoding) (or equivalently, unicode(s, encoding)).
If fullFilePath and path are currently a str type, you should figure out how they are encoded. For example, if the current encoding is utf-8, you would use:
path = path.decode('utf-8')
fullFilePath = fullFilePath.decode('utf-8')If this doesn't fix it, the actual issue may be that you are not using a Unicode string in your execute() call, try changing it to the following:
cur.execute(u"update docs set path = :fullFilePath where path = :path", locals())Make sure you've set your locale settings right before running the script from the shell, e.g.
$ locale -a | grep "^en_.\+UTF-8"
en_GB.UTF-8
en_US.UTF-8
$ export LC_ALL=en_GB.UTF-8
$ export LANG=en_GB.UTF-8Docs: man locale, man setlocale.