Resource punkt not found. Please use the NLTK Downloader to obtain the resource: >>> import nltk >>> nltk.download('punkt')
 Sebastian Wright
Sebastian Wright 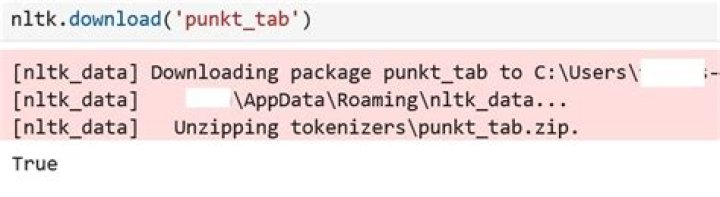
I have NLTK installed and it is going me error Resource punkt not found. Please use the NLTK Downloader to obtain the resource:
import nltk nltk.download('punkt') For more information see:
Attempted to load tokenizers/punkt/PY3/english.pickle
Searched in: - '/Users/divyanshundley/nltk_data' - '/Library/Frameworks/ - '/Library/Frameworks/ - '/Library/Frameworks/ - '/usr/share/nltk_data' - '/usr/local/share/nltk_data' - '/usr/lib/nltk_data' - '/usr/local/lib/nltk_data' - ''
and my code is
import nltk
nltk.download('punkt')
def tokenize(token): return nltk.word_tokenize(token);
tokenize("why is this not working?");3 Answers
Please download the below also. This will resolve your issue:
*nltk.download('punkt')
nltk.download('wordnet')
nltk.download('omw-1.4'*)
1Executing these lines in Jupyter Notebook allowed me to tokenize successfully.
(Executing these lines launches the NLTK downloader)import nltknltk.download()
From the menu I selected (d) Download then entered the "book" for the corpus to download, then (q) to quit.
(These lines then successfully tokenized the sentence)
from nltk.tokenize import word_tokenizeword_tokenize("Let's learn machine learning")
I simply find that punkt is just already in the directory:
"C:\Users\username\AppData\Roaming\nltk_data\tokenizers"
However, the nklt module only tries to search
"C:\Users\s1111\AppData\Roaming\nltk_data"
without the "tokenizers" directory. So, just find the punky file in the first directory and copy it to the second directory. No need to download any files.