Regex match entire words only
 Sophia Terry
Sophia Terry 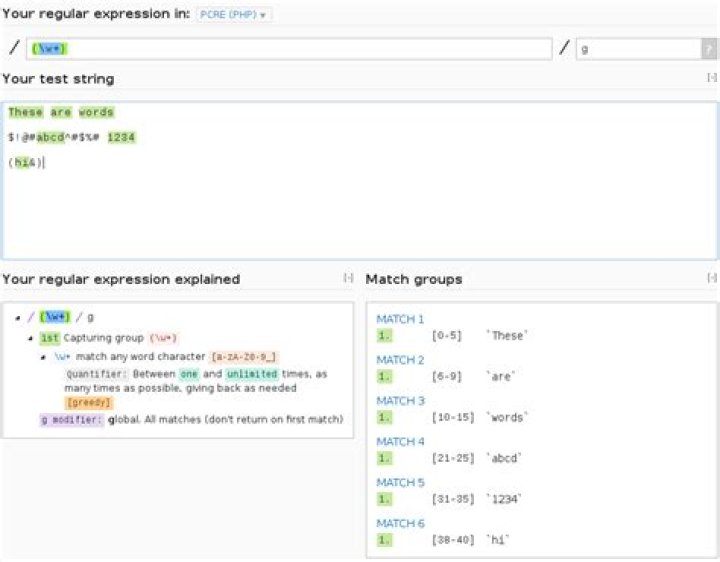
I have a regex expression that I'm using to find all the words in a given block of content, case insensitive, that are contained in a glossary stored in a database. Here's my pattern:
/($word)/iThe problem is, if I use /(Foo)/i then words like Food get matched. There needs to be whitespace or a word boundary on both sides of the word.
How can I modify my expression to match only the word Foo when it is a word at the beginning, middle, or end of a sentence?
7 Answers
Use word boundaries:
/\b($word)\b/iOr if you're searching for "S.P.E.C.T.R.E." like in Sinan Ünür's example:
/(?:\W|^)(\Q$word\E)(?:\W|$)/iTo match any whole word you would use the pattern (\w+)
Assuming you are using PCRE or something similar:
Above screenshot taken from this live example:
Matching any whole word on the commandline with (\w+)
I'll be using the phpsh interactive shell on Ubuntu 12.10 to demonstrate the PCRE regex engine through the method known as preg_match
Start phpsh, put some content into a variable, match on word.
el@apollo:~/foo$ phpsh
php> $content1 = 'badger'
php> $content2 = '1234'
php> $content3 = '$%^&'
php> echo preg_match('(\w+)', $content1);
1
php> echo preg_match('(\w+)', $content2);
1
php> echo preg_match('(\w+)', $content3);
0The preg_match method used the PCRE engine within the PHP language to analyze variables: $content1, $content2 and $content3 with the (\w)+ pattern.
$content1 and $content2 contain at least one word, $content3 does not.
Match a number of literal words on the commandline with (dart|fart)
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(dart|fart)', $gun1);
1
php> echo preg_match('(dart|fart)', $gun2);
1
php> echo preg_match('(dart|fart)', $gun3);
1
php> echo preg_match('(dart|fart)', $gun4);
0variables gun1 and gun2 contain the string dart or fart. gun4 does not. However it may be a problem that looking for word fart matches farty. To fix this, enforce word boundaries in regex.
Match literal words on the commandline with word boundaries.
el@apollo:~/foo$ phpsh
php> $gun1 = 'dart gun';
php> $gun2 = 'fart gun';
php> $gun3 = 'farty gun';
php> $gun4 = 'unicorn gun';
php> echo preg_match('(\bdart\b|\bfart\b)', $gun1);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun2);
1
php> echo preg_match('(\bdart\b|\bfart\b)', $gun3);
0
php> echo preg_match('(\bdart\b|\bfart\b)', $gun4);
0So it's the same as the previous example except that the word fart with a \b word boundary does not exist in the content: farty.
Using \b can yield surprising results. You would be better off figuring out what separates a word from its definition and incorporating that information into your pattern.
#!/usr/bin/perl
use strict; use warnings;
use re 'debug';
my $str = 'S.P.E.C.T.R.E. (Special Executive for Counter-intelligence,
Terrorism, Revenge and Extortion) is a fictional global terrorist
organisation';
my $word = 'S.P.E.C.T.R.E.';
if ( $str =~ /\b(\Q$word\E)\b/ ) { print $1, "\n";
}Output:
Compiling REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b" Final program: 1: BOUND (2) 2: OPEN1 (4) 4: EXACT (9) 9: CLOSE1 (11) 11: BOUND (12) 12: END (0) anchored "S.P.E.C.T.R.E." at 0 (checking anchored) stclass BOUND minlen 14 Guessing start of match in sv for REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b" against "S.P .E.C.T.R.E. (Special Executive for Counter-intelligence,"... Found anchored substr "S.P.E.C.T.R.E." at offset 0... start_shift: 0 check_at: 0 s: 0 endpos: 1 Does not contradict STCLASS... Guessed: match at offset 0 Matching REx "\b(S\.P\.E\.C\.T\.R\.E\.)\b" against "S.P.E.C.T.R.E. (Special Exec utive for Counter-intelligence,"... 0 | 1:BOUND(2) 0 | 2:OPEN1(4) 0 | 4:EXACT (9) 14 | 9:CLOSE1(11) 14 | 11:BOUND(12) failed... Match failed Freeing REx: "\b(S\.P\.E\.C\.T\.R\.E\.)\b"1
For Those who want to validate an Enum in their code you can following the guide
In Regex World you can use ^ for starting a string and $ to end it. Using them in combination with | could be what you want :
^(Male)$|^(Female)$
It will return true only for Male or Female case.
If you are doing it in Notepad++
[\w]+ Would give you the entire word, and you can add parenthesis to get it as a group. Example: conv1 = Conv2D(64, (3, 3), activation=LeakyReLU(alpha=a), padding='valid', kernel_initializer='he_normal')(inputs). I would like to move LeakyReLU into its own line as a comment, and replace the current activation. In notepad++ this can be done using the follow find command:
([\w]+)( = .+)(LeakyReLU.alpha=a.)(.+)and the replace command becomes:
\1\2'relu'\4 \n # \1 = LeakyReLU\(alpha=a\)\(\1\)The spaces is to keep the right formatting in my code. :)
use word boundaries \b,
The following (using four escapes) works in my environment: Mac, safari Version 10.0.3 (12602.4.8)
var myReg = new RegExp(‘\\\\b’+ variable + ‘\\\\b’, ‘g’)Get all "words" in a string
/([^\s]+)/g
Basically
^/smeans break on spaces (or match groups of non-spaces)
Don't forget thegfor Greedy
Try it:
"Not the answer you're looking for? Browse other questions tagged regex word-boundary or ask your own question.".match(/([^\s]+)/g)
→ (17) ['Not', 'the', 'answer', "you're", 'looking', 'for?', 'Browse', 'other', 'questions', 'tagged', 'regex', 'word-boundary', 'or', 'ask', 'your', 'own', 'question.']
1