Kubectl rollout restart for statefulset
 Andrew Henderson
Andrew Henderson 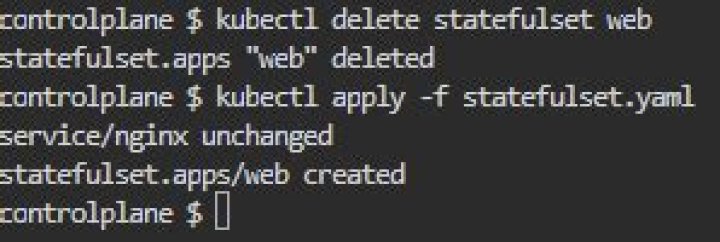
As per the kubectl docs, kubectl rollout restart is applicable for deployments, daemonsets and statefulsets. It works as expected for deployments. But for statefulsets, it restarts only one pod of the 2 pods.
✗ k rollout restart statefulset alertmanager-main (playground-fdp/monitoring) restarted
✗ k rollout status statefulset alertmanager-main (playground-fdp/monitoring)
Waiting for 1 pods to be ready...
Waiting for 1 pods to be ready...
statefulset rolling update complete 2 pods at revision alertmanager-main-59d7ccf598...
✗ kgp -l app=alertmanager (playground-fdp/monitoring)
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 21h
alertmanager-main-1 2/2 Running 0 20sAs you can see the pod alertmanager-main-1 has been restarted and its age is 20s. Whereas the other pod in the statefulset alertmanager, i.e., pod alertmanager-main-0 has not been restarted and it is age is 21h. Any idea how we can restart a statefulset after some configmap used by it has been updated?
[Update 1] Here is the statefulset configuration. As you can see the .spec.updateStrategy.rollingUpdate.partition is not set.
apiVersion: apps/v1
kind: StatefulSet
metadata: annotations: | {"apiVersion":"","kind":"Alertmanager","metadata":{"annotations":{},"labels":{"alertmanager":"main"},"name":"main","namespace":"monitoring"},"spec":{"baseImage":"10.47.2.76:80/alm/alertmanager","nodeSelector":{"":"linux"},"replicas":2,"securityContext":{"fsGroup":2000,"runAsNonRoot":true,"runAsUser":1000},"serviceAccountName":"alertmanager-main","version":"v0.19.0"}} creationTimestamp: "2019-12-02T07:17:49Z" generation: 4 labels: alertmanager: main name: alertmanager-main namespace: monitoring ownerReferences: - apiVersion: blockOwnerDeletion: true controller: true kind: Alertmanager name: main uid: 3e3bd062-6077-468e-ac51-909b0bce1c32 resourceVersion: "521307" selfLink: /apis/apps/v1/namespaces/monitoring/statefulsets/alertmanager-main uid: ed4765bf-395f-4d91-8ec0-4ae23c812a42
spec: podManagementPolicy: Parallel replicas: 2 revisionHistoryLimit: 10 selector: matchLabels: alertmanager: main app: alertmanager serviceName: alertmanager-operated template: metadata: creationTimestamp: null labels: alertmanager: main app: alertmanager spec: containers: - args: - --config.file=/etc/alertmanager/config/alertmanager.yaml - --cluster.listen-address=[$(POD_IP)]:9094 - --storage.path=/alertmanager - --data.retention=120h - --web.listen-address=:9093 - --web.external-url= - --web.route-prefix=/ - --cluster.peer=alertmanager-main-0.alertmanager-operated.monitoring.svc:9094 - --cluster.peer=alertmanager-main-1.alertmanager-operated.monitoring.svc:9094 env: - name: POD_IP valueFrom: fieldRef: apiVersion: v1 fieldPath: status.podIP image: 10.47.2.76:80/alm/alertmanager:v0.19.0 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 10 httpGet: path: /-/healthy port: web scheme: HTTP periodSeconds: 10 successThreshold: 1 timeoutSeconds: 3 name: alertmanager ports: - containerPort: 9093 name: web protocol: TCP - containerPort: 9094 name: mesh-tcp protocol: TCP - containerPort: 9094 name: mesh-udp protocol: UDP readinessProbe: failureThreshold: 10 httpGet: path: /-/ready port: web scheme: HTTP initialDelaySeconds: 3 periodSeconds: 5 successThreshold: 1 timeoutSeconds: 3 resources: requests: memory: 200Mi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /etc/alertmanager/config name: config-volume - mountPath: /alertmanager name: alertmanager-main-db - args: - -webhook-url= - -volume-dir=/etc/alertmanager/config image: 10.47.2.76:80/alm/configmap-reload:v0.0.1 imagePullPolicy: IfNotPresent name: config-reloader resources: limits: cpu: 100m memory: 25Mi terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /etc/alertmanager/config name: config-volume readOnly: true dnsPolicy: ClusterFirst nodeSelector: linux restartPolicy: Always schedulerName: default-scheduler securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccount: alertmanager-main serviceAccountName: alertmanager-main terminationGracePeriodSeconds: 120 volumes: - name: config-volume secret: defaultMode: 420 secretName: alertmanager-main - emptyDir: {} name: alertmanager-main-db updateStrategy: type: RollingUpdate
status: collisionCount: 0 currentReplicas: 2 currentRevision: alertmanager-main-59d7ccf598 observedGeneration: 4 readyReplicas: 2 replicas: 2 updateRevision: alertmanager-main-59d7ccf598 updatedReplicas: 23 Answers
You did not provide whole scenario. It might depends on Readiness Probe or Update Strategy.
StatefulSet restart pods from index 0 to n-1. Details can be found here.
Reason 1*
Statefulset have 4 update strategies.
- On Delete
- Rolling Updates
- Partitions
- Forced Rollback
In Partition update you can find information that:
If a partition is specified, all Pods with an ordinal that is greater than or equal to the partition will be updated when the StatefulSet’s
.spec.templateis updated. All Pods with an ordinal that is less than the partition will not be updated, and, even if they are deleted, they will be recreated at the previous version. If a StatefulSet’s.spec.updateStrategy.rollingUpdate.partitionis greater than its.spec.replicas, updates to its.spec.templatewill not be propagated to its Pods. In most cases you will not need to use a partition, but they are useful if you want to stage an update, roll out a canary, or perform a phased roll out.
So if somewhere in StatefulSet you have set updateStrategy.rollingUpdate.partition: 1 it will restart all pods with index 1 or higher.
Example of partition: 3
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 30m
web-1 1/1 Running 0 30m
web-2 1/1 Running 0 31m
web-3 1/1 Running 0 2m45s
web-4 1/1 Running 0 3m
web-5 1/1 Running 0 3m13sReason 2
Configuration of Readiness probe.
If your values of initialDelaySeconds and periodSeconds are high, it might take a while before another one will be restarted. Details about those parameters can be found here.
In below example, pod will wait 10 seconds it will be running, and readiness probe is checking this each 2 seconds. Depends on values it might be cause of this behavior.
readinessProbe: failureThreshold: 3 httpGet: path: / port: 80 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 2 successThreshold: 1 timeoutSeconds: 1Reason 3
I saw that you have 2 containers in each pod.
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 21h
alertmanager-main-1 2/2 Running 0 20sAs describe in docs:
Running- The Pod has been bound to a node, and all of the Containers have been created. At least one Container is still running, or is in the process of starting or restarting.
It would be good to check if everything is ok with both containers (readinessProbe/livenessProbe, restarts etc.)
You would need to delete it. Stateful set are removed following their ordinal index with the highest ordinal index first.
Also you do not need to restart pod to re-read updated config map. This is happening automatically (after some period of time).
2This might be related to your ownerReferences definition. You can try it without any owner and do the rollout again.