How to json_normalize a column with NaNs
 Emily Wong
Emily Wong 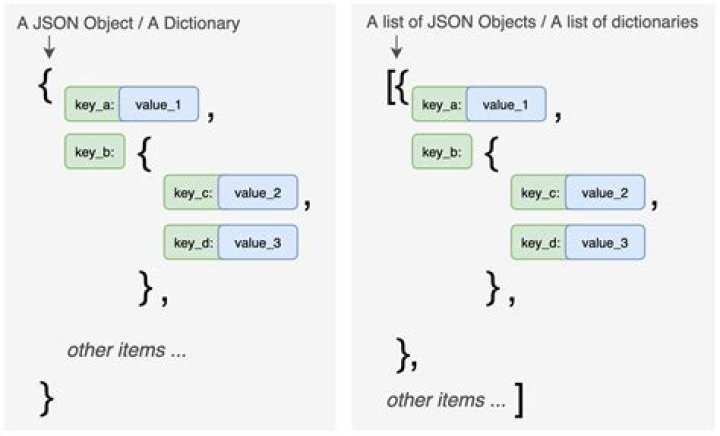
- This question is specific to columns of data in a
pandas.DataFrame - This question depends on if the values in the columns are
str,dict, orlisttype. - This question addresses dealing with the
NaNvalues, whendf.dropna().reset_index(drop=True)isn't a valid option.
Case 1
- With a column of
strtype, the values in the column must be converted todicttype, withast.literal_eval, before using.json_normalize.
import numpy as np
import pandas as pd
from ast import literal_eval
df = pd.DataFrame({'col_str': ['{"a": "46", "b": "3", "c": "12"}', '{"b": "2", "c": "7"}', '{"c": "11"}', np.NaN]}) col_str
0 {"a": "46", "b": "3", "c": "12"}
1 {"b": "2", "c": "7"}
2 {"c": "11"}
3 NaN
type(df.iloc[0, 0])
[out]: str
df.col_str.apply(literal_eval)Error:
df.col_str.apply(literal_eval) results in ValueError: malformed node or string: nanCase 2
- With a column of
dicttype, usepandas.json_normalizeto convert keys to column headers and values to rows
df = pd.DataFrame({'col_dict': [{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}, {"c": "11"}, np.NaN]}) col_dict
0 {'a': '46', 'b': '3', 'c': '12'}
1 {'b': '2', 'c': '7'}
2 {'c': '11'}
3 NaN
type(df.iloc[0, 0])
[out]: dict
pd.json_normalize(df.col_dict)Error:
pd.json_normalize(df.col_dict) results in AttributeError: 'float' object has no attribute 'items'Case 3
- In a column of
strtype, with thedictinside alist. - To normalize the column
- apply
literal_eval, because explode doesn't work onstrtype - explode the column to separate the
dictsto separate rows - normalize the column
- apply
df = pd.DataFrame({'col_str': ['[{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}]', '[{"b": "2", "c": "7"}, {"c": "11"}]', np.nan]}) col_str
0 [{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}]
1 [{"b": "2", "c": "7"}, {"c": "11"}]
2 NaN
type(df.iloc[0, 0])
[out]: str
df.col_str.apply(literal_eval)Error:
df.col_str.apply(literal_eval) results in ValueError: malformed node or string: nan1 Answer
- There is always the option to:
df = df.dropna().reset_index(drop=True)- That's fine for the dummy data here, or when dealing with a dataframe where the other columns don't matter.
- Not a great option for dataframes with additional columns that are required.
Case 1
- Since the column contains
strtypes, fillna with'{}'(astr)
import numpy as np
import pandas as pd
from ast import literal_eval
df = pd.DataFrame({'col_str': ['{"a": "46", "b": "3", "c": "12"}', '{"b": "2", "c": "7"}', '{"c": "11"}', np.NaN]}) col_str
0 {"a": "46", "b": "3", "c": "12"}
1 {"b": "2", "c": "7"}
2 {"c": "11"}
3 NaN
type(df.iloc[0, 0])
[out]: str
# fillna
df.col_str = df.col_str.fillna('{}')
# convert the column to dicts
df.col_str = df.col_str.apply(literal_eval)
# use json_normalize
df = df.join(pd.json_normalize(df.col_str)).drop(columns=['col_str'])
# display(df) a b c
0 46 3 12
1 NaN 2 7
2 NaN NaN 11
3 NaN NaN NaNCase 2
As of at least pandas 1.3.4, pd.json_normalize(df.col_dict) works without issue, at least for this simple example.
- Since the column contains
dicttypes, fillna with{}(not astr) - This needs to be filled using a dict-comprehension, since
fillna({})does not work
df = pd.DataFrame({'col_dict': [{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}, {"c": "11"}, np.NaN]}) col_dict
0 {'a': '46', 'b': '3', 'c': '12'}
1 {'b': '2', 'c': '7'}
2 {'c': '11'}
3 NaN
type(df.iloc[0, 0])
[out]: dict
# fillna
df.col_dict = df.col_dict.fillna({i: {} for i in df.index})
# use json_normalize
df = df.join(pd.json_normalize(df.col_dict)).drop(columns=['col_dict'])
# display(df) a b c
0 46 3 12
1 NaN 2 7
2 NaN NaN 11
3 NaN NaN NaNCase 3
- Fill the
NaNswith'[]'(astr) - Now
literal_evalwill work .explodecan be used on the column to separate thedictvalues to rows- Now the
NaNsneed to be filled with{}(not astr) - Then the column can be normalized
- For the case when the column is
listsofdicts, that aren'tstrtype, skip to.explode.
df = pd.DataFrame({'col_str': ['[{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}]', '[{"b": "2", "c": "7"}, {"c": "11"}]', np.nan]}) col_str
0 [{"a": "46", "b": "3", "c": "12"}, {"b": "2", "c": "7"}]
1 [{"b": "2", "c": "7"}, {"c": "11"}]
2 NaN
type(df.iloc[0, 0])
[out]: str
# fillna
df.col_str = df.col_str.fillna('[]')
# literal_eval
df.col_str = df.col_str.apply(literal_eval)
# explode
df = df.explode('col_str').reset_index(drop=True)
# fillna again
df.col_str = df.col_str.fillna({i: {} for i in df.index})
# use json_normalize
df = df.join(pd.json_normalize(df.col_str)).drop(columns=['col_str'])
# display(df) a b c
0 46 3 12
1 NaN 2 7
2 NaN 2 7
3 NaN NaN 11
4 NaN NaN NaN