How to find details like whether the mounted filesystem is read only or read-write with details of status related to the disk health?
 Matthew Barrera
Matthew Barrera 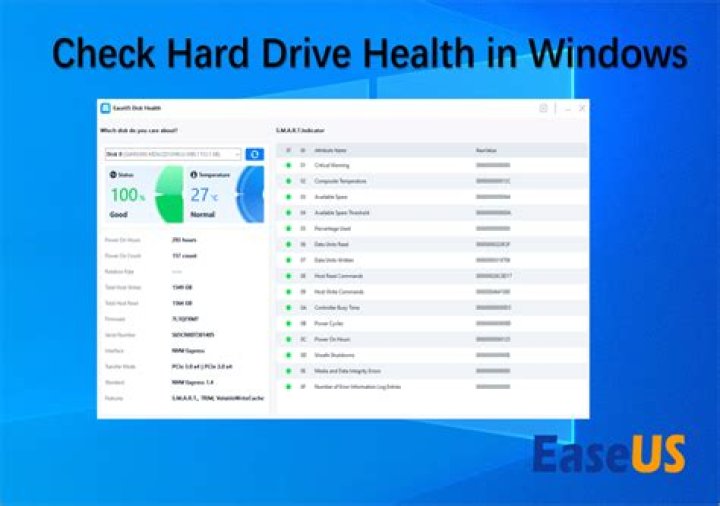
How to find details like whether the mounted file-system is read only or read-write?
In addition to it how to find details of the hard disk or partition health status without affecting the data of that mounted disk or partition?
3 Answers
Command mount will list all mounted partitions and will indicate whether they are mounted read only (ro) or read-write (rw).
There is no way to tell whether a filesystem is "healty" while mounted in a normal read-write mode. To determine whether a filesystem is healthy you need to use fsck (or a similar tool) and these require either unmounted filesystems or filesystems mounter read-only.
I guess you could look in the kernel log using command dmesg and look for messages like "journal replayed" - they will indicate that the filesystem has been mounted dirty.
The file /proc/mounts contains the neccessary information.
For instance, there I have an entry for my jump drive
/dev/sdb1 /media/xieerqi/Lexar vfat rw,nosuid,nodev,relatime,uid=1000,gid=1000,fmask=0022,dmask=0077,codepage=437,iocharset=iso8859-1,shortname=mixed,showexec,utf8,flush,errors=remount-ro 0 0Coma separated list of options and specificallyrw indicates that this is read-write mounted filesystem. For read-only it would say ro
you'll need a combination of tools, which I believe are bundled in the package smartmontools. This links holds a fairly nice plan.
Your first step should be to evaluate the SMART report of each drive using smartctl.
smartctl -a /dev/sdXassuming a standard SATA controller, with X being the actual drive identifierYour second step should be an extended drive self-test, smartctl is the way to go here as well:
smartctl --test=long /dev/sdXand after the test time has passed (between 60 and 240 minutes for most drives), read the results with the command in step 1.Your third step should be a drive conveyance test, if supported by your drive. You get an error from the following command if it is not supported:
smartctl --test=conveyance /dev/sdX. Results: see step 1.Up to this point, simply writing the whole drive would have been a bad idea, since bad sector remappings are done during write operations. In other words, the evidence of the drive failure might have been covered up.
Assuming that all steps above fail to find a problem, you should now use "badblocks" to scan your drives for write errors:
badblocks -nvs /dev/sdXThe above is a nondestructive test, use -wvs is the destructive alternative, may be a bit faster.
The ones I pay attention to on my laptop (with SSD drive, different disks have different S.M.A.R.T. tests)
5 Reallocated_Sector_Ct
183 Runtime_Bad_Block
184 End-to-End_Error
233 Media_Wearout_IndicatorEspecially the first indicator is nice, as it tells you how many bad sectors/blocks have been remapped on the disk.