How to find all occurrences of a substring?
 Sophia Terry
Sophia Terry 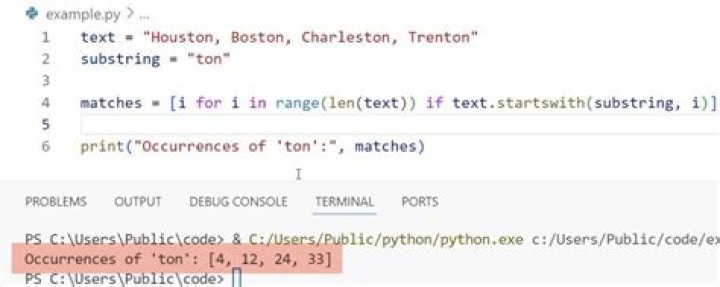
Python has string.find() and string.rfind() to get the index of a substring in a string.
I'm wondering whether there is something like string.find_all() which can return all found indexes (not only the first from the beginning or the first from the end).
For example:
string = "test test test test"
print string.find('test') # 0
print string.rfind('test') # 15
#this is the goal
print string.find_all('test') # [0,5,10,15]30 Answers
There is no simple built-in string function that does what you're looking for, but you could use the more powerful regular expressions:
import re
[m.start() for m in re.finditer('test', 'test test test test')]
#[0, 5, 10, 15]If you want to find overlapping matches, lookahead will do that:
[m.start() for m in re.finditer('(?=tt)', 'ttt')]
#[0, 1]If you want a reverse find-all without overlaps, you can combine positive and negative lookahead into an expression like this:
search = 'tt'
[m.start() for m in re.finditer('(?=%s)(?!.{1,%d}%s)' % (search, len(search)-1, search), 'ttt')]
#[1]re.finditer returns a generator, so you could change the [] in the above to () to get a generator instead of a list which will be more efficient if you're only iterating through the results once.
>>> help(str.find)
Help on method_descriptor:
find(...) S.find(sub [,start [,end]]) -> intThus, we can build it ourselves:
def find_all(a_str, sub): start = 0 while True: start = a_str.find(sub, start) if start == -1: return yield start start += len(sub) # use start += 1 to find overlapping matches
list(find_all('spam spam spam spam', 'spam')) # [0, 5, 10, 15]No temporary strings or regexes required.
6Here's a (very inefficient) way to get all (i.e. even overlapping) matches:
>>> string = "test test test test"
>>> [i for i in range(len(string)) if string.startswith('test', i)]
[0, 5, 10, 15]Again, old thread, but here's my solution using a generator and plain str.find.
def findall(p, s): '''Yields all the positions of the pattern p in the string s.''' i = s.find(p) while i != -1: yield i i = s.find(p, i+1)Example
x = 'banananassantana'
[(i, x[i:i+2]) for i in findall('na', x)]returns
[(2, 'na'), (4, 'na'), (6, 'na'), (14, 'na')]You can use re.finditer() for non-overlapping matches.
>>> import re
>>> aString = 'this is a string where the substring "is" is repeated several times'
>>> print [(a.start(), a.end()) for a in list(re.finditer('is', aString))]
[(2, 4), (5, 7), (38, 40), (42, 44)]but won't work for:
In [1]: aString="ababa"
In [2]: print [(a.start(), a.end()) for a in list(re.finditer('aba', aString))]
Output: [(0, 3)]Come, let us recurse together.
def locations_of_substring(string, substring): """Return a list of locations of a substring.""" substring_length = len(substring) def recurse(locations_found, start): location = string.find(substring, start) if location != -1: return recurse(locations_found + [location], location+substring_length) else: return locations_found return recurse([], 0)
print(locations_of_substring('this is a test for finding this and this', 'this'))
# prints [0, 27, 36]No need for regular expressions this way.
2If you're just looking for a single character, this would work:
string = "dooobiedoobiedoobie"
match = 'o'
reduce(lambda count, char: count + 1 if char == match else count, string, 0)
# produces 7Also,
string = "test test test test"
match = "test"
len(string.split(match)) - 1
# produces 4My hunch is that neither of these (especially #2) is terribly performant.
1this is an old thread but i got interested and wanted to share my solution.
def find_all(a_string, sub): result = [] k = 0 while k < len(a_string): k = a_string.find(sub, k) if k == -1: return result else: result.append(k) k += 1 #change to k += len(sub) to not search overlapping results return resultIt should return a list of positions where the substring was found. Please comment if you see an error or room for improvment.
This does the trick for me using re.finditer
import re
text = 'This is sample text to test if this pythonic '\ 'program can serve as an indexing platform for '\ 'finding words in a paragraph. It can give '\ 'values as to where the word is located with the '\ 'different examples as stated'
# find all occurances of the word 'as' in the above text
find_the_word = re.finditer('as', text)
for match in find_the_word: print('start {}, end {}, search string \'{}\''. format(match.start(), match.end(), match.group()))This thread is a little old but this worked for me:
numberString = "onetwothreefourfivesixseveneightninefiveten"
testString = "five"
marker = 0
while marker < len(numberString): try: print(numberString.index("five",marker)) marker = numberString.index("five", marker) + 1 except ValueError: print("String not found") marker = len(numberString)You can try :
>>> string = "test test test test"
>>> for index,value in enumerate(string): if string[index:index+(len("test"))] == "test": print index
0
5
10
15Whatever the solutions provided by others are completely based on the available method find() or any available methods.
What is the core basic algorithm to find all the occurrences of a substring in a string?
def find_all(string,substring): """ Function: Returning all the index of substring in a string Arguments: String and the search string Return:Returning a list """ length = len(substring) c=0 indexes = [] while c < len(string): if string[c:c+length] == substring: indexes.append(c) c=c+1 return indexesYou can also inherit str class to new class and can use this function below.
class newstr(str):
def find_all(string,substring): """ Function: Returning all the index of substring in a string Arguments: String and the search string Return:Returning a list """ length = len(substring) c=0 indexes = [] while c < len(string): if string[c:c+length] == substring: indexes.append(c) c=c+1 return indexesCalling the method
newstr.find_all('Do you find this answer helpful? then upvote this!','this')
When looking for a large amount of key words in a document, use flashtext
from flashtext import KeywordProcessor
words = ['test', 'exam', 'quiz']
txt = 'this is a test'
kwp = KeywordProcessor()
kwp.add_keywords_from_list(words)
result = kwp.extract_keywords(txt, span_info=True)Flashtext runs faster than regex on large list of search words.
This function does not look at all positions inside the string, it does not waste compute resources. My try:
def findAll(string,word): all_positions=[] next_pos=-1 while True: next_pos=string.find(word,next_pos+1) if(next_pos<0): break all_positions.append(next_pos) return all_positionsto use it call it like this:
result=findAll('this word is a big word man how many words are there?','word')src = input() # we will find substring in this string
sub = input() # substring
res = []
pos = src.find(sub)
while pos != -1: res.append(pos) pos = src.find(sub, pos + 1)You can try :
import re
str1 = "This dress looks good; you have good taste in clothes."
substr = "good"
result = [_.start() for _ in re.finditer(substr, str1)]
# result = [17, 32]The pythonic way would be:
mystring = 'Hello World, this should work!'
find_all = lambda c,s: [x for x in range(c.find(s), len(c)) if c[x] == s]
# s represents the search string
# c represents the character string
find_all(mystring,'o') # will return all positions of 'o'
[4, 7, 20, 26]
>>> This is solution of a similar question from hackerrank. I hope this could help you.
import re
a = input()
b = input()
if b not in a: print((-1,-1))
else: #create two list as start_indc = [m.start() for m in re.finditer('(?=' + b + ')', a)] for i in range(len(start_indc)): print((start_indc[i], start_indc[i]+len(b)-1))Output:
aaadaa
aa
(0, 1)
(1, 2)
(4, 5)if you only want to use numpy here is a solution
import numpy as np
S= "test test test test"
S2 = 'test'
inds = np.cumsum([len(k)+len(S2) for k in S.split(S2)[:-1]])- len(S2)
print(inds)def find_index(string, let): enumerated = [place for place, letter in enumerate(string) if letter == let] return enumeratedfor example :
find_index("hey doode find d", "d") returns:
[4, 7, 13, 15]Not exactly what OP asked but you could also use the split function to get a list of where all the substrings don't occur. OP didn't specify the end goal of the code but if your goal is to remove the substrings anyways then this could be a simple one-liner. There are probably more efficient ways to do this with larger strings; regular expressions would be preferable in that case
# Extract all non-substrings
s = "an-example-string"
s_no_dash = s.split('-')
# >>> s_no_dash
# ['an', 'example', 'string']
# Or extract and join them into a sentence
s_no_dash2 = ' '.join(s.split('-'))
# >>> s_no_dash2
# 'an example string'Did a brief skim of other answers so apologies if this is already up there.
def count_substring(string, sub_string): c=0 for i in range(0,len(string)-2): if string[i:i+len(sub_string)] == sub_string: c+=1 return c
if __name__ == '__main__': string = input().strip() sub_string = input().strip() count = count_substring(string, sub_string) print(count)I runned in the same problem and did this:
hw = 'Hello oh World!'
list_hw = list(hw)
o_in_hw = []
while True: o = hw.find('o') if o != -1: o_in_hw.append(o) list_hw[o] = ' ' hw = ''.join(list_hw) else: print(o_in_hw) breakIm pretty new at coding so you can probably simplify it (and if planned to used continuously of course make it a function).
All and all it works as intended for what i was doing.
Edit: Please consider this is for single characters only, and it will change your variable, so you have to create a copy of the string in a new variable to save it, i didnt put it in the code cause its easy and its only to show how i made it work.
if you want to use without re(regex) then:
find_all = lambda _str,_w : [ i for i in range(len(_str)) if _str.startswith(_w,i) ]
string = "test test test test"
print( find_all(string, 'test') ) # >>> [0, 5, 10, 15]Here's a solution that I came up with, using assignment expression (new feature since Python 3.8):
string = "test test test test"
phrase = "test"
start = -1
result = [(start := string.find(phrase, start + 1)) for _ in range(string.count(phrase))]Output:
[0, 5, 10, 15]To find all the occurence of a character in a give string and return as a dictionaryeg: hello result :{'h':1, 'e':1, 'l':2, 'o':1}
def count(string): result = {} if(string): for i in string: result[i] = string.count(i) return result return {}or else you do like this
from collections import Counter def count(string): return Counter(string)Try this it worked for me !
x=input('enter the string')
y=input('enter the substring')
z,r=x.find(y),x.rfind(y)
while z!=r: print(z,r,end=' ') z=z+len(y) r=r-len(y) z,r=x.find(y,z,r),x.rfind(y,z,r)please look at below code
#!/usr/bin/env python
# coding:utf-8
'''黄哥Python'''
def get_substring_indices(text, s): result = [i for i in range(len(text)) if text.startswith(s, i)] return result
if __name__ == '__main__': text = "How much wood would a wood chuck chuck if a wood chuck could chuck wood?" s = 'wood' print get_substring_indices(text, s)By slicing we find all the combinations possible and append them in a list and find the number of times it occurs using count function
s=input()
n=len(s)
l=[]
f=input()
print(s[0])
for i in range(0,n): for j in range(1,n+1): l.append(s[i:j])
if f in l: print(l.count(f))You can easily use:
string.count('test')!Cheers!
3