Hive query failed on Tez DAG did not succeed due to VERTEX_FAILURE
 Andrew Henderson
Andrew Henderson 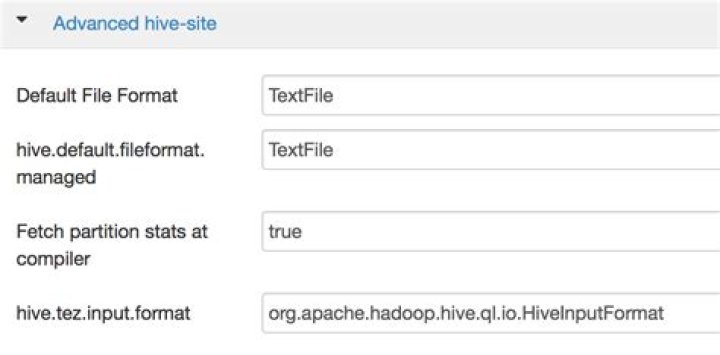
I have a basic setup of Ambari 2.5.3 and HDP 2.6.3 and tried to run some simple queries below. I don't understand why it failed. Can you help?
[root@demo demo]# beeline
Beeline version 1.2.1000.2.6.3.0-235 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000/default hive hive
Connecting to jdbc:hive2://localhost:10000/default
Connected to: Apache Hive (version 1.2.1000.2.6.3.0-235)
Driver: Hive JDBC (version 1.2.1000.2.6.3.0-235)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000/default> create table test2 (id int, desc varchar(40));
No rows affected (1.216 seconds)
0: jdbc:hive2://localhost:10000/default> insert into table test2 values (1,"aa"),(2,"bb");
INFO : Tez session hasn't been created yet. Opening session
INFO : Dag name: insert into table test2 ...(1,"aa"),(2,"bb")(Stage-1)
ERROR : Status: Failed
ERROR : Vertex failed, vertexName=Map 1, vertexId=vertex_1514250829950_0001_1_00, diagnostics=[Vertex vertex_1514250829950_0001_1_00 [Map 1] killed/failed due to:ROOT_INPUT_INIT_FAILURE, Vertex Input: values__tmp__table__1 initializer failed, vertex=vertex_1514250829950_0001_1_00 [Map 1], java.lang.NullPointerException at org.apache.hadoop.mapred.FileInputFormat.getBlockIndex(FileInputFormat.java:388) at org.apache.hadoop.mapred.FileInputFormat.getSplitHostsAndCachedHosts(FileInputFormat.java:579) at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:359) at org.apache.hadoop.hive.ql.io.HiveInputFormat.addSplitsForGroup(HiveInputFormat.java:311) at org.apache.hadoop.hive.ql.io.HiveInputFormat.getSplits(HiveInputFormat.java:413) at org.apache.hadoop.hive.ql.exec.tez.HiveSplitGenerator.initialize(HiveSplitGenerator.java:155) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:273) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:266) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:266) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:253) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
]
ERROR : DAG did not succeed due to VERTEX_FAILURE. failedVertices:1 killedVertices:0
Error: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Vertex failed, vertexName=Map 1, vertexId=vertex_1514250829950_0001_1_00, diagnostics=[Vertex vertex_1514250829950_0001_1_00 [Map 1] killed/failed due to:ROOT_INPUT_INIT_FAILURE, Vertex Input: values__tmp__table__1 initializer failed, vertex=vertex_1514250829950_0001_1_00 [Map 1], java.lang.NullPointerException at org.apache.hadoop.mapred.FileInputFormat.getBlockIndex(FileInputFormat.java:388) at org.apache.hadoop.mapred.FileInputFormat.getSplitHostsAndCachedHosts(FileInputFormat.java:579) at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:359) at org.apache.hadoop.hive.ql.io.HiveInputFormat.addSplitsForGroup(HiveInputFormat.java:311) at org.apache.hadoop.hive.ql.io.HiveInputFormat.getSplits(HiveInputFormat.java:413) at org.apache.hadoop.hive.ql.exec.tez.HiveSplitGenerator.initialize(HiveSplitGenerator.java:155) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:273) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:266) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:266) at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:253) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745)
]DAG did not succeed due to VERTEX_FAILURE. failedVertices:1 killedVertices:0 (state=08S01,code=2)UPDATE 1
This is what I have in Hive config
2 Answers
I have faced the same issue, just change the execution engine to MR and it will work.
3NPE could be related to mapred.FileInputFormat. The inputformat name matters. Try setting org.apache.hadoop.hive.ql.io.HiveInputFormat for hive.input.format.
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
0