Convert UTF-8 octets to unicode code points
 Matthew Martinez
Matthew Martinez 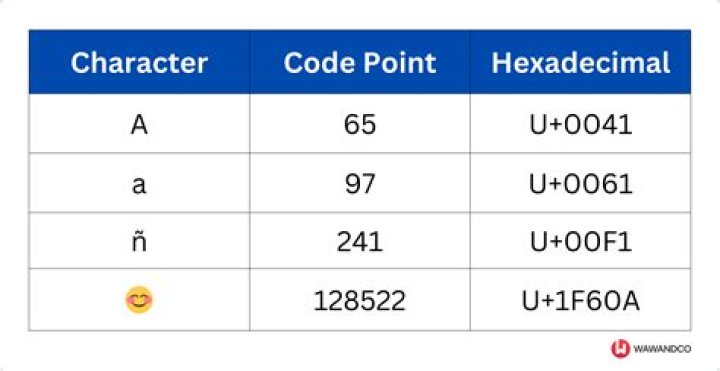
I have a set of UTF-8 octets and I need to convert them back to unicode code points. How can I do this in python.
e.g. UTF-8 octet ['0xc5','0x81'] should be converted to 0x141 codepoint.
44 Answers
Python 3.x:
In Python 3.x, str is the class for Unicode text, and bytes is for containing octets.
If by "octets" you really mean strings in the form '0xc5' (rather than '\xc5') you can convert to bytes like this:
>>> bytes(int(x,0) for x in ['0xc5', '0x81'])
b'\xc5\x81'You can then convert to str (ie: Unicode) using the str constructor...
>>> str(b'\xc5\x81', 'utf-8')
'Ł'...or by calling .decode('utf-8') on the bytes object:
>>> b'\xc5\x81'.decode('utf-8')
'Ł'
>>> hex(ord('Ł'))
'0x141'Pre-3.x:
Prior to 3.x, the str type was a byte array, and unicode was for Unicode text.
Again, if by "octets" you really mean strings in the form '0xc5' (rather than '\xc5') you can convert them like this:
>>> ''.join(chr(int(x,0)) for x in ['0xc5', '0x81'])
'\xc5\x81'You can then convert to unicode using the constructor...
>>> unicode('\xc5\x81', 'utf-8')
u'\u0141'...or by calling .decode('utf-8') on the str:
>>> '\xc5\x81'.decode('utf-8')
u'\u0141'In lovely 3.x, where all strs are Unicode, and bytes are what strs used to be:
>>> s = str(bytes([0xc5, 0x81]), 'utf-8')
>>> s
'Ł'
>>> ord(s)
321
>>> hex(ord(s))
'0x141'Which is what you asked for.
1l = ['0xc5','0x81']
s = ''.join([chr(int(c, 16)) for c in l]).decode('utf8')
s
>>> u'\u0141'>>> "".join((chr(int(x,16)) for x in ['0xc5','0x81'])).decode("utf8")
u'\u0141'